RAG 幻觉调优场景问题
📌代码版本:请以最新代码版本为准,保持同步更新,获取最新功能与修复。PIG AI 提供主流算法与工具,帮助用户快速搭建 RAG 解决方案,简化开发流程,但具体效果仍需用户自行探索与优化。🎯 文无第一,武无第二:RAG 文本输出效果因场景和数据不同,无法统一评判最佳模型和参数配置,需根据实际需求不断调优,因地制宜灵活调整。🔑 持续迭代:RAG 优化是一个长期工程,需持续实验、反馈和改进。

模型篇
厂商接口优先
- 即使使用相同版本的 DeepSeek R1 满血版,调用 DeepSeek 官方 API 和 本地或政务云自部署 的效果往往相差甚远,甚至可以说是”差了一星半点”。为什么会这样?
聊天模型优先
DeepSeek R1 很火,但真的适合 RAG 业务吗? 🔹 响应时间长,用户体验差 DeepSeek R1 在推理阶段的计算复杂度较高,导致推理时间 + 响应时间过长,直接影响用户体验。在 RAG 业务中,快速检索并生成准确回答至关重要,而长时间的等待会降低系统可用性。 🔹 问题发散度高,不利于 RAG 任务 DeepSeek R1 理解能力强,但发散性高,意味着它在处理问题时可能会自行推理和扩展,甚至与检索结果无关。而 RAG 的核心目标是让大模型基于检索到的正确答案进行总结,过度发散反而影响回答的精准度。 🔹 推荐 Qwen-Max 系列作为 RAG 主模型 Qwen-Max 系列在 RAG 任务中的指令遵循率更高,即用户给出的内容就是生成的主要依据,不会过度”发挥”或自行推理。对于严格依赖事实的应用场景(如法律、医疗、企业知识库),这类模型能更精准地遵循检索结果,提供高质量的回答。大参数集优先
在大语言模型(LLM)中,模型参数集(Parameter Set)指的是模型在训练过程中学习到的权重和偏置(Weights & Biases),这些参数决定了模型如何处理输入并生成输出。可以简单理解为: 📌 参数 = 模型的”知识” 📌 参数越多,模型的表达能力越强 所以不要祈求 ollama 运行一个 7b 14b 的小模型能有太好的推理效果,大模型也遵循基本的社会规则一分钱一分货私有模型选择
vLLM 相比 Ollama 更适合私有化部署,其核心优势在于更高效的资源利用,适用于高并发和大规模推理场景。然而,vLLM 的上手成本相对较高,需要更深入的环境配置和优化,而 Ollama 则更适合快速上手和本地轻量级推理。
| 模型类型 | 模型名称 | 说明 |
|---|---|---|
| 聊天模型 | qwen2.5:72b | 72b 参数量聊天模型,更准确但需要更多资源 |
| 推理模型 | deepseek-r1:32b | R1 推理模型 |
| 向量模型 | bge-m3:latest | 中文没得选,也就它了 |
| 视觉模型 | qwen2.5vl:32b |
注意运行 70b 模型为生产级模型,需要 GPU 80G+ 的显存,无法在普通 CPU 条件推理,模型推理速度(可以理解为提问响应速度)取决于硬件配置。
 PIG AI 正在测试 QwQ 32b,欢迎大家反馈
PIG AI 正在测试 QwQ 32b,欢迎大家反馈
配置篇
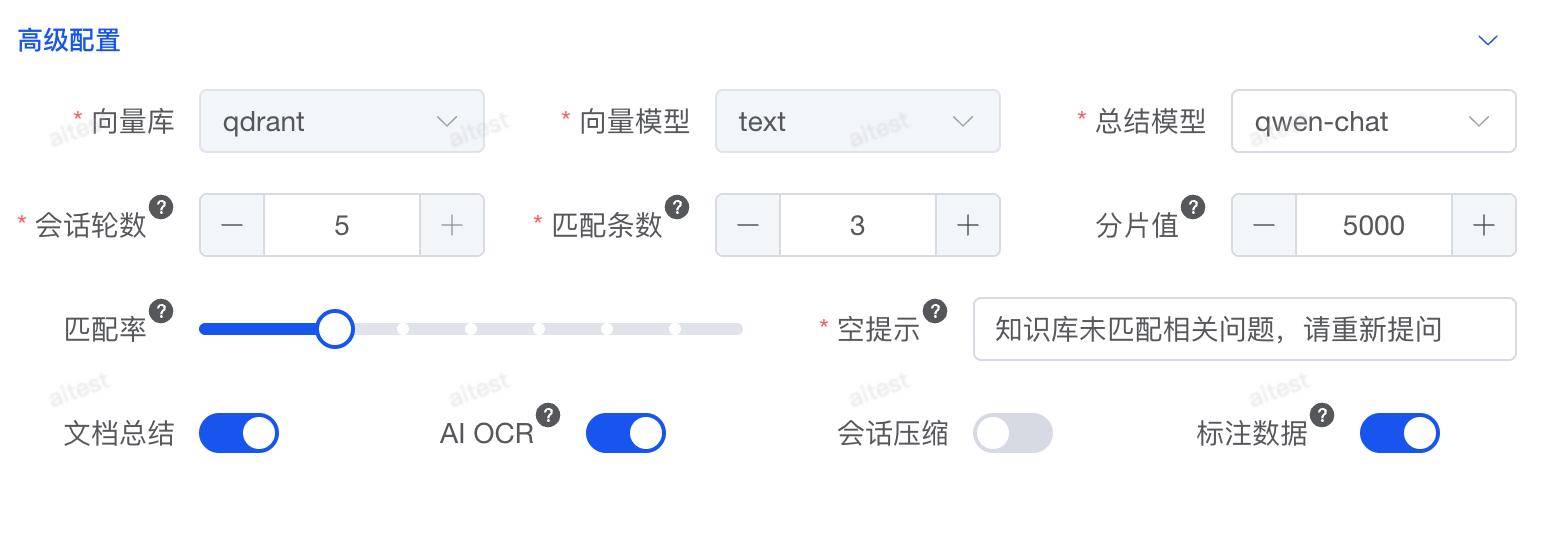
要不断调整如下参数进行策略,RAG 生成的文本效果,文无第一武无第二
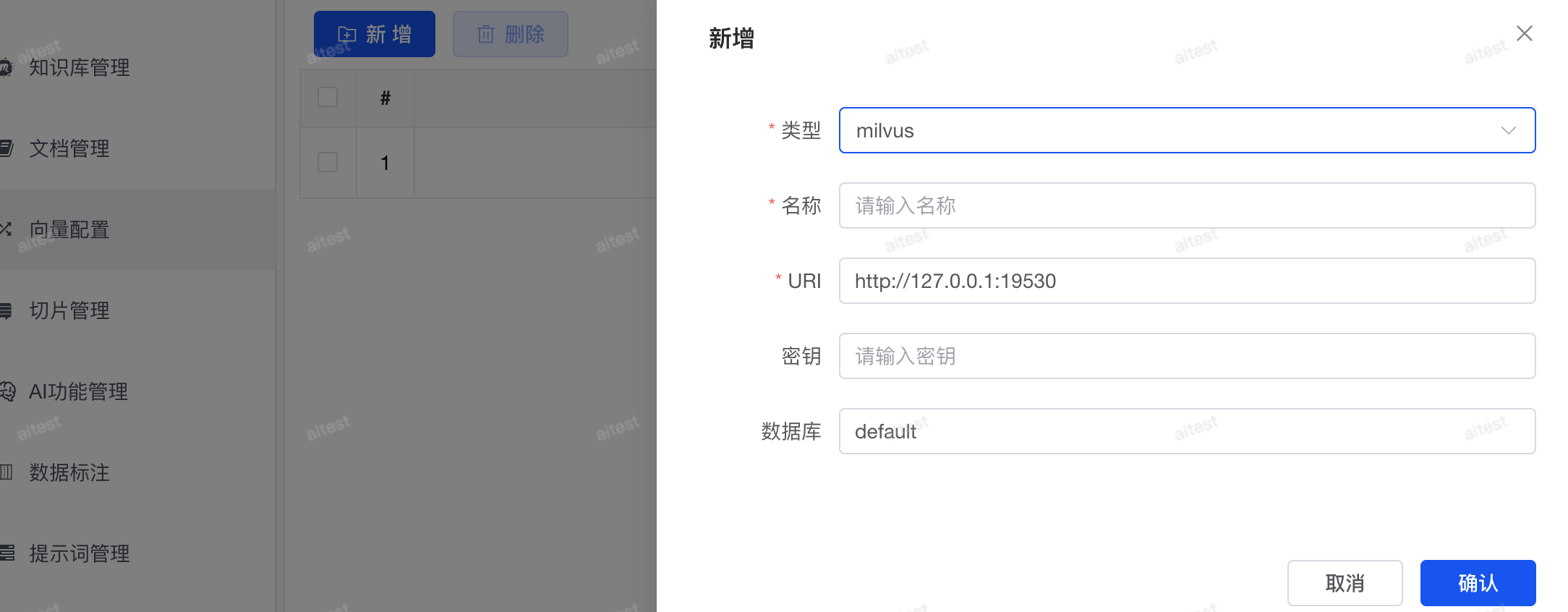
向量库选择
在入门阶段,我们通常使用 docker run qdrant 作为向量库的快速上手方案。但如果你需要更强大的功能,推荐使用 Milvus,虽然它需要更多资源,但功能更强大。可以直接参考官方文档,运行 Milvus 的单机版本:Milvus 单机部署指南。 Milvus 的优势:支持向量检索 + 全文检索的混合检索,即先进行向量搜索,再结合全文搜索优化结果,提高搜索的准确性和相关性。部署 Milvus 2.5+ 服务时,强烈建议仔细阅读 Milvus 官方文档,确保硬件配置符合要求。
匹配率
用户的提问会与向量库中的数据进行 余弦相似度(cosine similarity) 计算,并返回匹配度最高的结果。只有相似度超过设定阈值的内容才会被保留。 相似度阈值设置建议- 如果你的资料较多,建议将阈值设置在 70% 以上,以减少无关结果,提高检索精准度。
- 阈值过低 可能会引入不相关内容,影响回答质量;阈值过高 可能导致部分相关内容被过滤掉,需要根据业务需求调整。
匹配条数
当相似度满足设定阈值后,可能会返回多条匹配结果。此时需要设置返回的条数,以确保检索的精准性和可读性。条数设置建议- 如果你的资料较多,建议取 1-2 条,避免信息过载,提高回答的相关性和准确性。
- 如果资料较少,可以适当增加返回条数,以提供更多参考信息。
切片数值
切片数值指的是文档分割后每个片段的大小,因为大模型无法一次性处理过长的文本。 但并不是切片越大,准确率就越高。建议将切片大小控制在 500-2000 之间,并进行调整测试。例如,如果文档中包含大量相似概念的名称,切片过大可能会导致模型推理错误增加。 调整切片大小的建议:- 如果资料内容高度相似,建议缩小切片大小,减少混淆。
- 切片越小,大模型的推理速度越快,但可能影响上下文完整性。
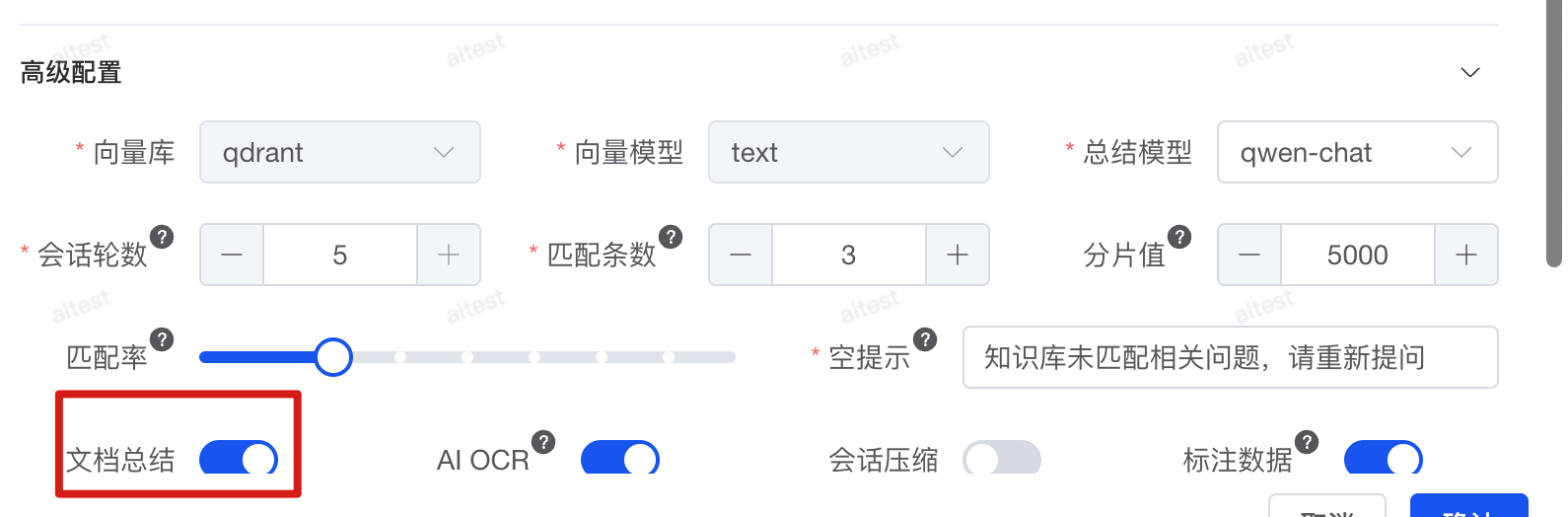
文档总结
切片后,文档可能会丢失上下文。为提升效果,可以在切片前先生成整篇文档的摘要,并将其附加到每个切片中,以提供全局背景信息。 但需要注意:如果文档内容相似度较高,不建议启用总结,因为相似度查询可能返回多条相近结果,反而容易导致模型产生幻觉。提示词篇
PIG AI 在设计时充分考虑了各类模型的兼容性,默认采用英文提示词以确保通用性。针对国内部分模型,建议根据实际情况对提示词进行适当微调,以进一步提升效果。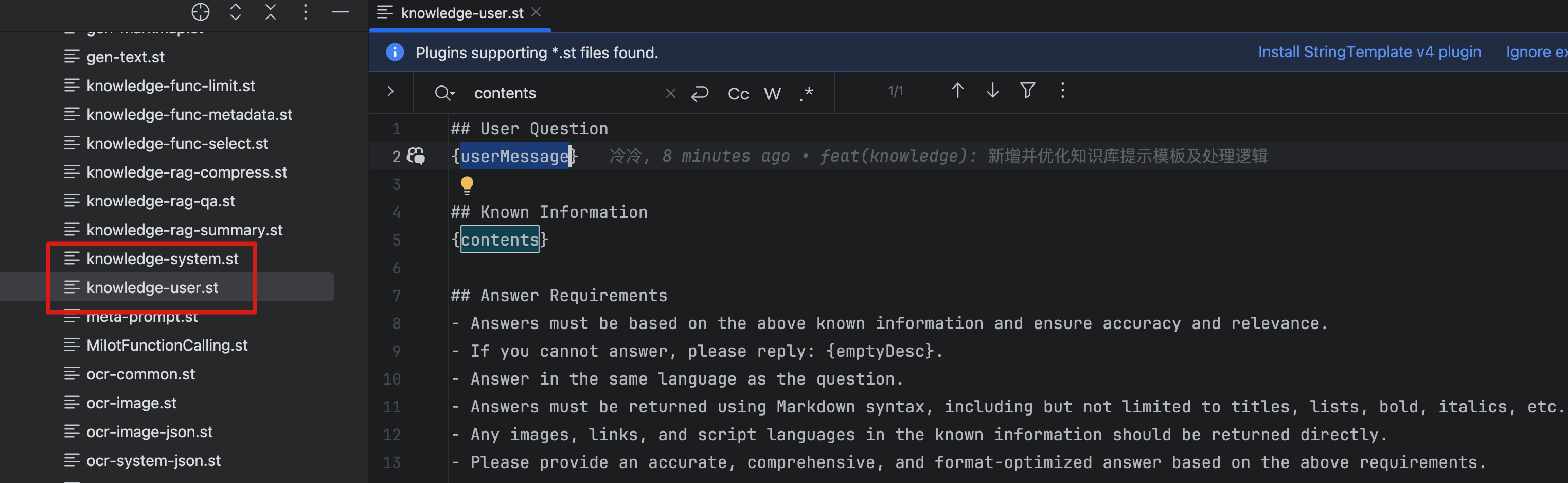
代码篇
提升 Office 文档识别质量
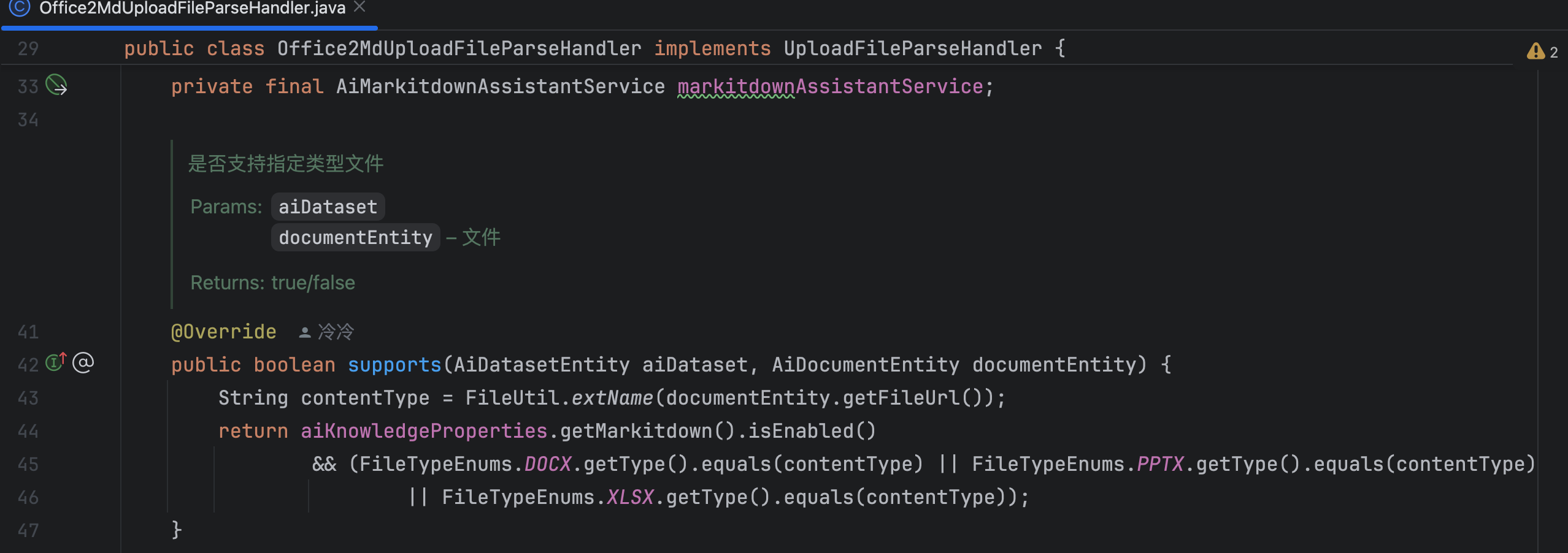
系统默认使用 POI/Tika 等Java工具提取 Office 文档内容时,会丢失原始格式信息,返回的纯文本可能影响后续处理效果。建议通过以下方式优化: 实现建议:- 部署使用我们开源的 office2md 工具(基于微软 MarkItDown 实现)
- 支持 DOCX/XLSX/PPTX 等格式转标准 Markdown
- 保留表格、列表、标题等关键格式信息
- 转换后的 Markdown 文本可提升大模型理解效果
提升文本向量质量
- 文档切片以后,可以在每片中关联原有的文档文件名信息,让每篇答案给大模型的时候都知道上下文语义
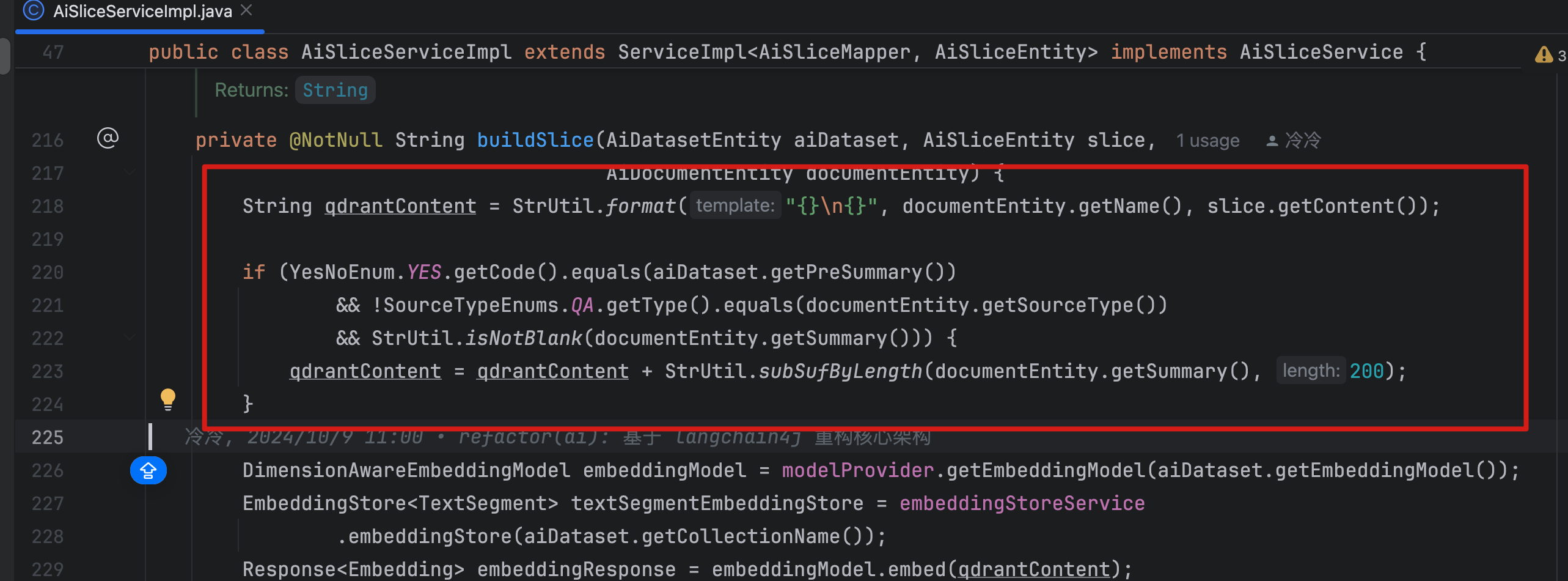
- 文档总结
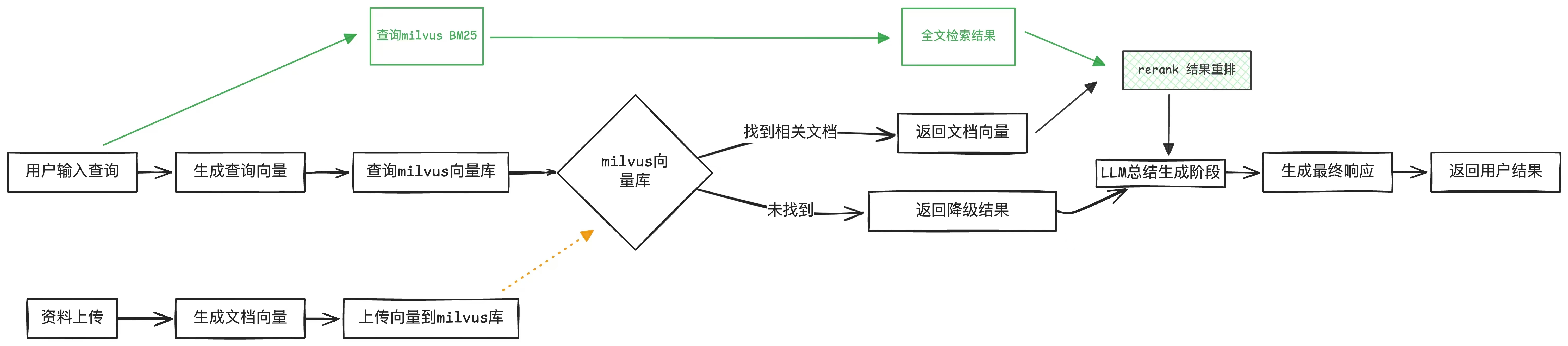
RAG 问答逻辑 (必须看)
所有逻辑代码均在 Q2AVectorRagChatHandler